
Fikiran manusia mempunyai had pada jumlah data yang boleh dikumpulkan dan diurus, tetapi mesin mampu menangani perkara ini dengan lebih baik daripada kita. Jadi sekarang kami cuba menjadikan mesin lebih pintar dengan membenarkan mereka belajar sendiri, tetapi untuk tujuan apa?
- Google I/O 2017: semua yang kami pelajari setakat ini
- Mengapa melabur dalam rumah pintar? 4 sebab mengapa kami fikir ia adalah idea yang baik
Apakah pembelajaran mesin?
Pembelajaran mesin (kadangkala dipanggil “pembelajaran automatik” atau “pembelajaran pintar”) adalah, seperti namanya, tentang membuat mesin atau sistem yang mampu belajar sendiri. Ini menandakan perbezaan yang ketara daripada pengaturcaraan komputer klasik, yang terdiri daripada manusia yang memberi perintah dan mesin yang melaksanakan perintah itu. Dalam pembelajaran mesin, mesin dapat menyesuaikan diri dengan situasi dan dengan itu belajar sendiri. Untuk ini berlaku, ia bukan sahaja mengenai algoritma perisian tetapi komponen perkakasan yang boleh memegangnya sendiri juga sangat penting, seperti cip TPU yang diumumkan oleh Google semasa Google I/O minggu lepas.
Campur tangan manusia dalam pengaturcaraan tidak sempurna kerana evolusi program (penambahan peraturan baru) boleh menyebabkan konflik dengan kod sedia ada, mengakibatkan ketidakstabilan. Jika sistem melakukan “berkembang” sendiri, ia tidak akan melakukan sesuatu yang bodoh (dalam teori…). Setelah berkata demikian, pembelajaran mesin sedang dibangunkan dalam banyak bidang lain, yang akan kami kembalikan kemudian.
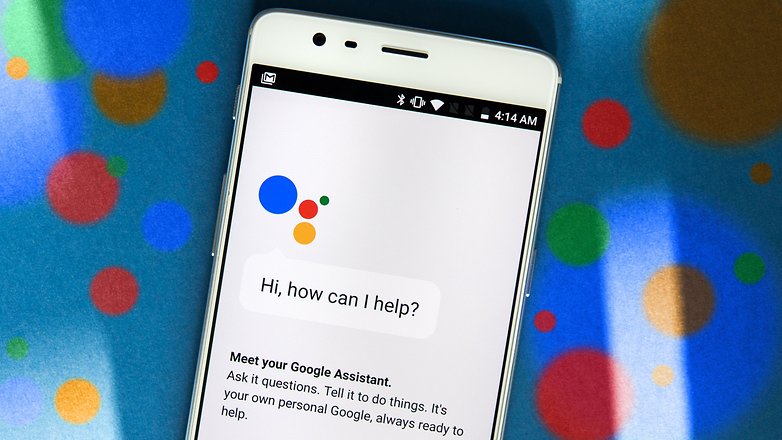
Google Assistant menggunakan teknologi Pembelajaran Mesin. © NextPit
Apakah perbezaan antara pembelajaran mesin dan kecerdasan buatan?
Walaupun pembelajaran mesin dan Kecerdasan Buatan bukanlah konsep yang sama sekali berbeza, ia juga tidak betul-betul sama. Pembelajaran Mesin boleh diringkaskan sebagai keupayaan mesin untuk menyesuaikan diri dengan situasi dan berkembang dengan sendirinya. Dalam erti kata lain, ia adalah salah satu proses yang diperlukan untuk kecerdasan buatan, yang seterusnya, adalah sistem autonomi.
Kita ambil contoh kereta autonomi – jadi kereta yang boleh pergi dari titik A ke titik B mengikut kod lebuh raya. Ini melibatkan kecerdasan buatan kerana mesin mampu menyesuaikan diri. Sekiranya ia telah diprogramkan untuk belajar dan memerhati untuk menyesuaikan diri dengan lalu lintas atau situasi yang berbeza, maka ini akan menjadi pembelajaran mesin. Jika ia telah diprogramkan untuk mengikuti berbilion peraturan pratakrif yang kekal tetap sehingga terdapat kemas kini, maka itu adalah kecerdasan buatan tanpa pembelajaran mesin.
Jelas sekali, pembelajaran mesin mempunyai potensi tertinggi untuk meningkatkan kecerdasan buatan dan ia memberikan kita peranti yang berfungsi dalam jangka panjang.
Pembelajaran mesin mempunyai potensi tertinggi untuk meningkatkan kecerdasan buatan
Apakah gunanya pembelajaran mesin?
Titik utama pembelajaran mesin adalah untuk membenarkan sistem komputer bertindak balas sendiri untuk melindungi dirinya atau rangkaian daripada serangan siber. Terdapat banyak kelebihan untuk ini, termasuk saintis komputer tidak lagi perlu disambungkan pada masa serangan untuk menangani masalah tersebut. Seperti kebanyakan teknologi moden yang lain, pembelajaran mesin bertujuan untuk akhirnya menjadi arus perdana untuk digunakan oleh sesiapa sahaja dan tidak kekal berorientasikan kepada khalayak khusus sahaja.
Ini adalah laluan yang disasarkan oleh pembelajaran mesin, digunakan dalam pelbagai sektor yang, seperti yang anda boleh bayangkan, mempunyai lebih banyak persamaan daripada yang dilihat pada mulanya. Semasa ucaptama Google I/O minggu lepas, Google menjelaskan bahawa ia menggunakan konsep ini dalam apl Google Photosnya. Yang terakhir belajar daripada cara anda menggunakan aplikasi dan jelas menggunakan data yang tersedia pada telefon anda (foto, nama dll) dan cuba menawarkan anda pengalaman yang anda fikirkan anda harapkan daripadanya.
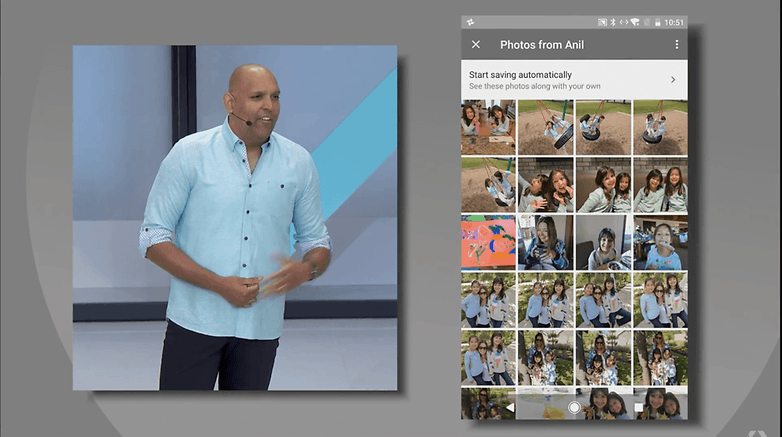
Google tahu cara menyesuaikan diri. © Tangkapan skrin: ANDROIDPIT
Strategi Google tidak terhad kepada Google Photos: strateginya adalah untuk menyatukan kebanyakan (atau mungkin semua?) perkhidmatannya. Wajah strategi ini jelas kelihatan seperti kecerdasan buatan: Pembantu Google. Pembantu belajar daripada semua yang diperhatikan dan ekosistem Google hanya meningkatkan kualiti maklumat yang tersedia (dan oleh itu potensi untuk penyesuaian).
- Petua dan kiat Google Assistant: semua yang anda perlu tahu daripada pemula hingga pakar
Satu teknologi yang menarik tetapi anda tidak sepatutnya terlalu selesa
“Adalah menggoda untuk menolak tanggapan tentang mesin yang sangat pintar sebagai fiksyen sains semata-mata. Tetapi ini akan menjadi satu kesilapan, dan kemungkinan kesilapan terburuk kita dalam sejarah. […] Malangnya, ia juga mungkin yang terakhir, melainkan kita belajar bagaimana untuk mengelakkan risiko”. Inilah yang difikirkan oleh ahli fizik Stephen Hawking tentang kecerdasan buatan yang, mari kita ingatkan anda, adalah kemuncak pembelajaran mesin. Oleh itu, akibat teknologi ini penting tetapi perlu mengekalkan beberapa elemen dalam pandangan kita.
Mengikut definisi, pembelajaran mesin belajar, jadi jika ia bertujuan untuk mengetahui tentang anda (seperti yang berlaku dengan Google), kita sudah tentu harus bertanya kepada diri sendiri soalan etika, sekali gus memasuki konflik dengan pragmatisme moden. Adakah boleh diterima bahawa seseorang (atau lebih tepatnya sesuatu) boleh mengakses begitu banyak maklumat tentang kita? Seperti yang dinyatakan oleh rakan sekerja saya Hans-Georg, kita tidak sepatutnya lupa bahawa Google dan beberapa agensi AS (jabatan kerajaan) juga mempunyai akses kepada data ini.

Pembelajaran mesin: serangan komputer atau pertahanan sistem? © ANDROIDPIT
Sudut lain yang perlu dipertimbangkan ialah kesannya terhadap masyarakat. Seperti yang ditunjukkan oleh rakan sekerja saya, Stefan dalam tanggapannya tentang Google I/O, Google Assistant menjadi sejenis “pusat”, satu titik hubungan untuk semua tindakan anda (meminta arahan, memesan makanan, dsb.). Selain daripada akibat pada interaksi sosial kita (yang kita hanya akan dapat melihat kesannya dalam jangka masa panjang), kita juga boleh mempertimbangkan konsep “mesin yang berfikir”, bolehkah teknologi ini menggantikan manusia? Saya tidak bermaksud ini sebagai fiksyen sains tetapi sebaliknya dari perspektif profesional: mesin sudah menggantikan manusia untuk banyak tugas, pembelajaran mesin boleh terus mendorong momentum ini. Lebih-lebih lagi, Google amat sedar akan kesan ini terhadap pekerjaan memandangkan firma itu juga mengambil peluang di Google I/O untuk melancarkan perkhidmatan Google Jobs baharunya, portal pencari kerja.
Jadi sebagai kesimpulan, jangan kita lupa fakta yang jelas: teknologi mematuhi peraturan orang yang menciptanya. Jika ia boleh digunakan untuk kebaikan, ia boleh digunakan untuk kejahatan. Sudah tentu, kita tidak tinggal di Terminator, alam semesta (didorong oleh mesin), tetapi konflik sibernetik boleh berkembang dengan cara yang sama sekali berbeza.
Pendek kata, sistem pembelajaran mesin sangat berguna dan mempunyai masa depan yang panjang, tetapi penjimatan masa dan penjimatan usaha yang disertakan bersamanya harus dipandang ringan.
Pada pendapat anda, di manakah pembelajaran mesin akan menjadi yang paling berguna? Di manakah ia akan mempunyai kesan yang paling besar? Beritahu kami pendapat anda dalam ulasan di bawah.
